Mamba
Introduced in Linear-Time Sequence Modeling with Selective State Spaces.
Mamba is an efficient sequential model, that combines the strengths of [[Transformer]]s and [[Recurrent Neural Network]]s. It can also be seen as a general, learnable non-LTI filter. It builds on top of the State Space Model, adding a selection mechanism which improves the compression of the continuous memory state.
Overview¶
The classic [[Transformer]] architecture is limited in two ways: 1. Anything outside the context window isn't considered at all. 2. Compute scales quadratically with respect to the window length.
Thus the authors propose to add a selection mechanism to the State Space Model to combine the continuous memory with the strengths of attention in transformers. The normal SSM must be an LTI System, being invariant to time and input, so the recurrent state could be computed via convolution. Mamba circumvents this short-coming through the use of an optimized scan which computes the model recurrently in linear time. This allows Mamba to selectively attend to the current input without having to remember (cache) the previous inputs. Also, this attention is based on the continuous memory state and not on just a limited time-window.
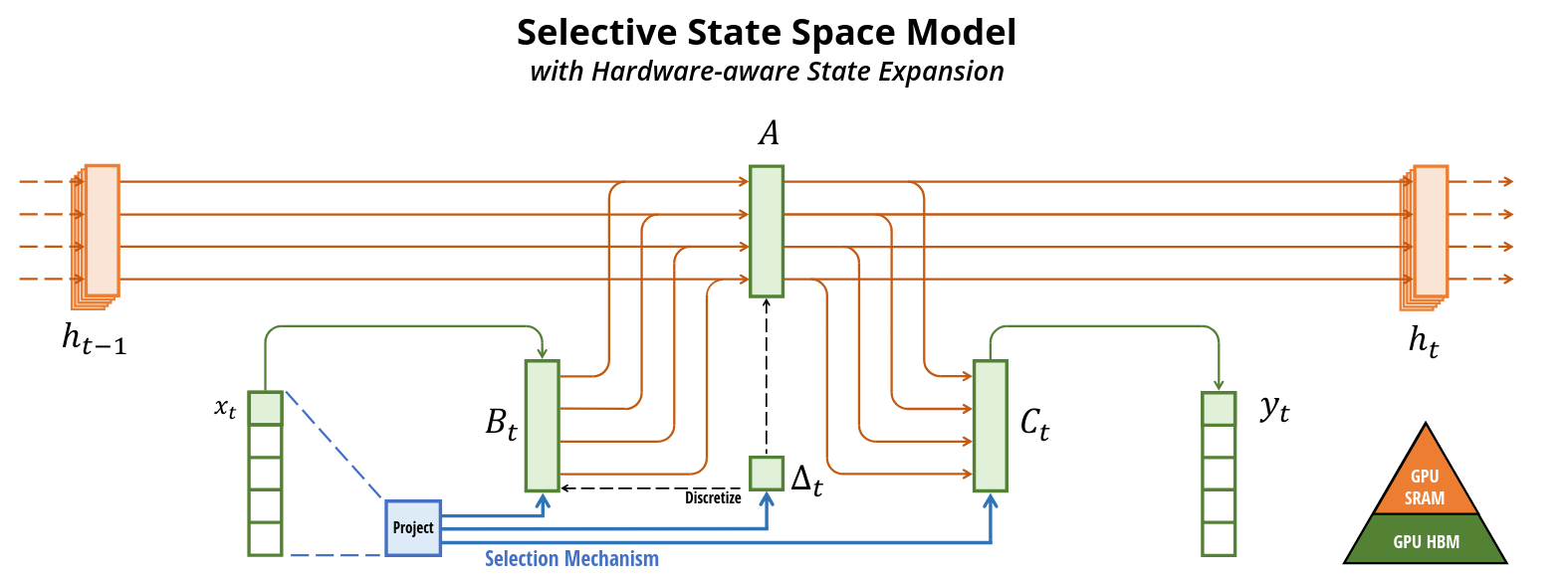
The figure shows the SSM with the newly proposed selection mechanism (blue). The SSM assumes the learned matrices A, B, C and \(\Delta t\) to be constant across time. Mamba allows the matrices to change depending on the input by efficiently expanding the continuous memory \(h_t\) in SRAM.
Optimization¶
Mamba can not make use of the dual representation of SSMs, which enables the convolutional processing of the recurrent process. The authors provide optimizations to make the recurrent computation just as feasable:
-
Hardware Specialization: Usually, neural networks are processed in the High Bandwidth Memory (HBM) of the GPU because of its capacity. The authors of Mamba propose to load \(\Delta\), A, B and C from the HBM into the SRAM, which is the cache directly located within the GPU die. While having a much lower capacity, the cache is directly available to the GPU during processing with minimal latency. Mamba uses a fused kernel to compute the discretization, scan and multiplication with C in a single kernel directly in SRAM.
-
Scan Algorithm: The parallel scan algorithm (Baloch 1990) is an algorithm that converts any sequentially applied associative operation into a much more efficient parallel operation. It does so by iteratively computing and aggregating partial results. This can algorithm can be used to efficiently compute the matrix multiplications of the recurrence.
-
Recomputation: For [[Backpropagation]], the intermediate states of the continuous memory are required. However, storing and reading them requires writing and reading \(BLDN\) elements from the slow HBM. In contrast, the costs of loading the inputs and outputs to the SRAM and recomputing the intermediate states only costs \(2\cdot (BLN+DN)\) reads, which is a significant speed up.