Existing Technology
Current products and research into multi-speaker speech enhancement are focused on learning-based approaches. Gaze-directed beamforming has been explored, but is limited to traditional signal processing approaches. An alternative to gaze fixation, called Auditory Attention Decoding, uses EEG/EOG signals to identify active speakers. Neuro-inspired approaches mostly explore network topology and [[Spiking Neural Networks]]. Audio-visual fusion techniques have been shown to increase robustness of SE in multi-speaker scenarios. The efficacy of assistive hearing devices have been evaluated by rating listening effort using questionnaires, but also via electrical signals and oxygenation in the brain.
State of Research¶
Speech Enhancement¶
Real-time Speech Enhancement¶
Audio delays between enhanced speech and actual speech become noticeable at 2-5ms, and objectionable/unpleasent at ~10ms. This effect is due to the interaction of direct and amplified sound, creating a pattern of alternating constructive and desctructive interference (comb filter). A latency in the sub-2ms area is also required for successful phase-locking in the auditory cortex.
Having a low-latency and low-resource model for speech enhancement is ongoing research and unlikely to be feasible for the current research project.
Future-frame prediction can be used for ~0ms latency speech enhancement and performance on par with non-causal models, compensating for the computational lag of the system. However, a study by Microsoft deems this approach ineffective due to decreased generalization and it being limited to predictive mapping methods.
Implication: Light, low-latency models will be a requirement for the glasses. A closed-ear solution likely is simpler so comb filtering is less pronounced.
Audio-Visual Speech Enhancement¶
It has been shown that congruence of audiovisual information is important for to reduce cognitive load and faster recognition time of speech in multi-speaker scenarios. Audio-visual models usually employ a two-stream extraction phase, in which acoustic and visual features are created. These features/embeddings are the fused via concatenation or attention mechanisms. Multi-speaker tracking is improved by employing audio-visual fusion. Real-time Audio Visual Speech Enhancement (RAVEN) fuses embeddings of audio and video to improve speech enhancement in noisy multi-speaker scenarios. Using audio-visual input has been shown to improve multi-speaker speech separation.
An alternative to beamforming is presented in Google's Looking to Listen model which creates speaker specific masks from audio-visual input streams. Google's MoXaRt (2026) provides a user interface to control the volume of speakers or musical instrument within the environment. It uses audio-visual fusion for speaker separation, first training a strong teacher model and then distill a faster student model for inference, with E2E latency of 2s. They use Oculus Quest 3.
Implication: Audio-visual fusion seems for speech enhancement and has neurological basis. Research project should be different to Google's research direction.
Multi-channel Speech Enhancement¶
Multi-channel signal processing is key for source separation as it allows exploiting the spatial structure of the input signal via the ITD and ILD. DNNs have shown exceptional performance in source separation tasks even in single channel scenarios (BioCPPNet). Combining spatial and tempo-spectral filtering in a single non-linear model outperforms linear spatial filtering (i.e. beamformer) with a non-linear postprocessing, showing that DNNs are very capable in processing multi-channel audio signals.
Preserving binaural cues in the output requires additional consideration.
Implication: Multi-channel input likely best option. Spatial output might be additional challenge outside of research focus?
Auditory Attention Decoding (AAD)¶
Several techniques explore the identification of the target speaker via auditory attention decoding. This is a highly relevant topic in current signal processing research, as signified by it being the first problem to appear in the IEEE ICASSP´s SP Grand Challenges. The challenge focuses on using EEG data for identifying the target speaker, but other methods have also been explored. EEG-based attention decoding has the potential to be very non-intrusive. While full-net EEGs allow for very high accuracy attention prediction, in-ear EEG solutions already allow for ~60% accuracy.
DARNet forms the baseline for the SP Grand Challenge and achieves a 91% accuracy in speaker identification in a 0.1s window and 97% in a 2s window. A comparison of eye tracking vs Electrooculography (EOG) for gaze tracking shows that eye tracking performs superior. More modern approaches however try to predict the target speaker directly, instead of utilizing the gaze fixation. Gaze tracking can also be facilitated by hybrid approaches using both EEG and eye tracking.
Implication: The ICASSP grand challenge highlights relevance, glasses with eye tracking as a well-performing alternative to AAD, where real-world usability seems not realistic yet.
Gaze-directed Speaker Enhancement¶
Gaze-tracking has shown improvements across numerous HCI use cases and has been shown to be a faster, more accurate and more natural way of selecting target speakers when compared to pointing or button pressing. There is evidence for the potential benefit of beamforming based on gaze tracking. A 2021 master thesis evaluated gaze-directed beamforming, showing improvements in speech intelligibility scores. A direct comparison of using gaze fixation vs head direction for beamforming shows that gaze fixation performs well in static target speaker scenarios, but limited in (fast) moving target speaker scenarios. Cochlearity fully implements gaze directed beamforming using a frame-mounted microphone array and a combination of MVDR and delay-and-sum beamforming. This work also includes introduction with great references into gaze-directed beamforming. Highly accurate eye tracking has been shown essential in effectively steering beamformers.
Gaze tracking has drawbacks, for example when the target is moving quickly or the gaze might wander while talking. For these cases, gaze-contingent selection might prove useful. Combining head and eye position might improve gaze tracking. Tim Rolff is looking into gaze anticipation, which might pair well with target speaker prediction?
Implication: Gaze-controlled beamforming with glasses as a real-world application not explored, promising pathway. Combines HCI, SP and CN/NI well.
Neural Auditory Processing¶
Spiking Domain¶
In [[Spiking Neural Networks]], neurons repeatedly integrate input activates and fire if the activation over time has exceeded some threshold. This is biologically more realistic than classical ANNs. SNNs have the advantage of being very energy efficient, requiring only a fraction of computational and IO operations. However, they require neuromorphic hardware to actually realize these benefits, as SNNs can only be simulated on standard silicon chips.
For static inputs like images, a rate encoding is used, which treats input magnitude as frequencies, representing high-magnitude activations as fast-firing neurons. ANNs can be converted into SNNs with only minor performance degradation. SNNs enable the application of bio-inspired approaches, especially the analysis of oscillatory patterns and frequency multiplexing. Auditory information and especially speech are efficiently encoded in the brain using phase of firing, suggesting the efficacy of SNNs for speech processing.
Implication: SNNs are promising path for energy and computationally efficient neural networks. However, the requirement for specialized neuromorphic hardware makes the integration with a smart glass device unfeasible. Even if available, integrating the specialized sensory hardware required for glasses is unrealistic.
Cortical Oscillation¶
In auditory tasks, an increase in theta-band activity and decrease in alpha- and beta-band activity can be observed. In opposition, visual tasks are characterized by a dependency on higher frequency bands. Rhythmic audio-visual tasks create meta-oscillations in the frequency-band amplitude, with energy density shifting into higher frequency-bands for visual and lower frequency-bands for auditory tasks. This implies a relevance of different oscillation frequencies for audio-visual fusion.
Cortical oscillations suggest the efficacy of a rhythmic amplifiication/inhibition in neural architectures. Furthermore, these oscillations phase-lock with temporal edges in speech (syllables, phonmes), which has been explored in the spiking domain to produce more human like speech comprehension. Stimuli-detection seems to correlate inversely with theta-band activity: If the amplitude is low, stimuli are detected more easily, if the amplitude is high, stimuli are missed more often. This suggests a rhythmic inhibitory gating mechanism.
BioOSS presents methods to apply and examine oscillatory dynamics (also in ANNs like LinOSS) in hierarchical periodic signal, making AI models more explainable. This approach is supported by research that suggests auditory encoding via frequency mutliplexingin the brain.
Implication: Emphasizing/Attenuating effects of cortical oscillations might inform and be verified by ANNs. This helps improving the explainability of neurological and AI models alike. Since SNNs are unfeasible for the current research project, exploring other ways of employing oscillatory systems like LinOSS might be promissing.
Neural Topology¶
Effortful cognitive tasks require multi-modal processing, which is facilitated by the Global Neural Workspace topology: Sensory inputs are processed by peripheral modules, and integrated in a central workspace. Feedback loops inform sensory attention through excititory and inhibitory feedback loops. In humans, a pronounced cortical axis between outer sensory areas and inner integration area can be observed.
Implication: Pronounced GNW topology in humans might be crucial for speech understanding, integration and verification via ANNs.
Neuro-inspired Neural Networks¶
It has proven useful to look at human cognition to better understand auditory processing and improve assistive hearing devices. Thomas Lunner has been leading specialist in this field. There is also a potentially relevant Signal Processing Magazine.
The Natural Sounds & Neural Coding Lab directed by Kamal Sen uses computational probabilistic signal processing models to investigate mechanisms of auditory processing in the brain and conversely apply these insights to explore brain-inspired sound processing for hearing assistive devices. This is directly in line with the current projects research proposal.
The Biologically Oriented Sound Segregation Algorithm (BOSSA) (nature pub) model directly applies a brain-inspired network topology in the spiking domain. It achieves comparable performance to an optimized 16 microphone-array beamformer with only 2 microphones. In a follow-up, the BOSSA model is combined with [[Automatic Speech Recognition (ASR)]] model [[Whisper]] to improve ASR accuracy in multi-speaker scenarios.
They also show the importance of gaze fixation on the target speaker for speech comprehension (similar paper). The lab seems to be working on integrating gaze tracking into the BOSSA model.
Implication: BOSSA model focuses on GNW topology in spiking domain. For low-latency requirement, classical networks in magnitude domain likely better and not in competition with BOSSA research.
Other¶
Research into foundation models suggests that speech enhancement might also benefit from large pre-trained networks. The BOSSA model mentioned above shows that fine-tuning foundation models like Whisper with a neuroinspired frontend can improve model performance.
The listening effort can be rated via questionnaires but also via measurement of the oxygenation in the Prefrontal Cortex (fNIRS neuroimaging) or measurement of the Alpha oscillations via EEGs.
Latency will likely be a problem, as commercial products have access to specialized on-device ships.
Commercial Products¶
Commercial hearing-assistive products fall into several categories
Assistive Glasses¶
Hearing-assistive glasses have the advantage of supporting multi-modal input and output and more spaced out microphone arrays. They typically fall into three categories: - Glasses that enhance the speaker, utilizing the viewing direction. - Glasses that transcribe the speaker, projecting captions of the speech into the lenses. - Glasses that are multi-media consumption devices. They may support both speaker enhancement and transcription, but often with higher latency.
Nuance Audio Glasses¶
Source: https://www.nuanceaudio.com
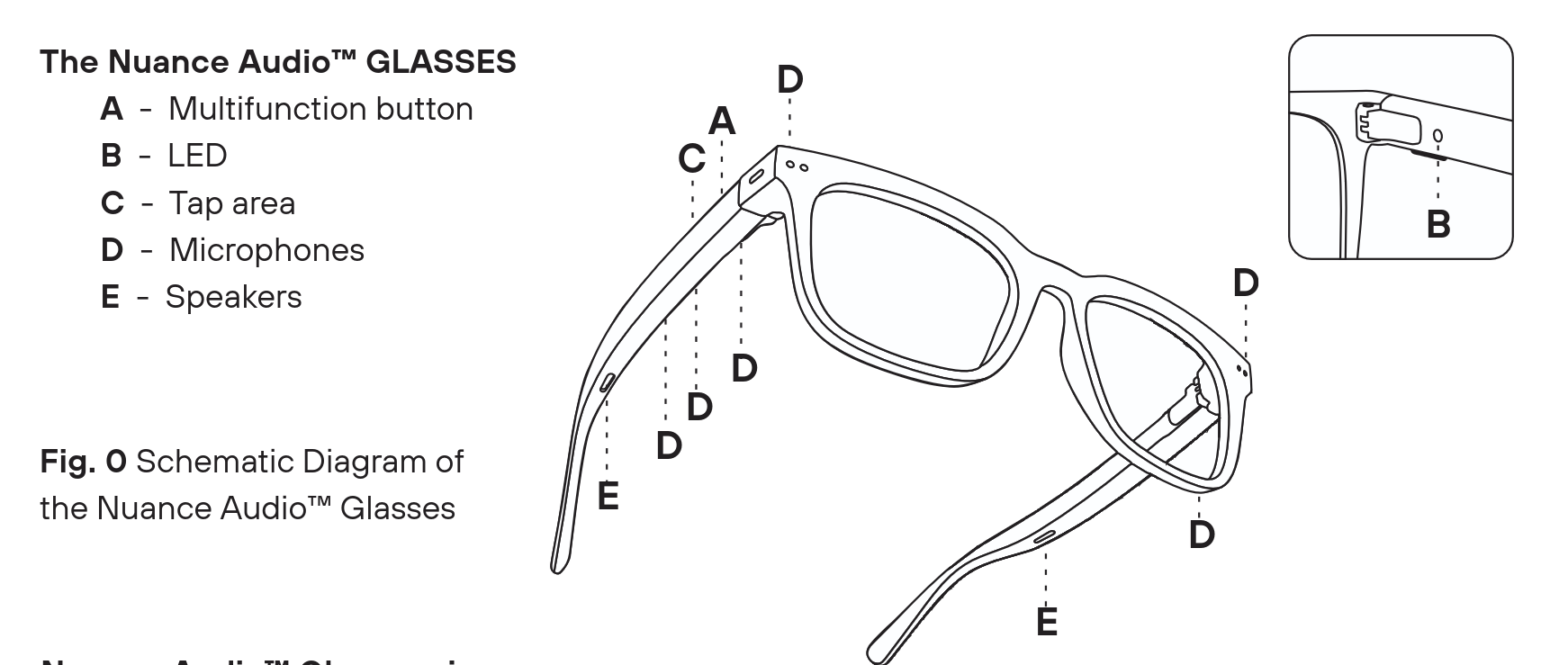
Uses directional microphones, beamforming and noise suppression to improve speech comprehension in cocktail party scenarios (office, conferences, parties, restaurants). The uses the head-direction for speech enhancement. Has in-frame open-ear speakers and dual front-facing microphones. Glasses can be configured via… - remote control - on-frame touch button - phone app
Configuration options are: - Noise suporession level - Volume - Modes (360 vs frontal) - Presets: - Preset A: Flat mild hearing loss. Slightly amplifies sounds across low to high pitches - Preset B: Sloping mild hearing loss. Amplification in the higher pitches - Preset C: Sloping moderate hearing loss. Amplification in the higher pitches with increased volume - Preset D: Flat moderate hearing loss. Slightly amplifies sounds across low to high pitches with increased volume
Has user calibration: Glasses play short bursts of sound, then user reads pre-configured sentences aloud. Target is to reduce acoustic feedback. Probably some approximation of [[Head-related Transfer Function (HRTF)]]. The glasses also allow for tracking of noise level via app, so noise suppression level can be adjusted accordingly (manual adjustment). Works for people with mild to severe hearing loss.
Might serve as baseline of commercially available products.
Meta Ray-Ban Glasses¶
Source: - https://www.meta.com/de/ai-glasses/ray-ban-meta/ - https://www.ray-ban.com/germany/electronics/RW4012ray-ban%20meta%20wayfarer%20-%20gen%202-grau%20transparent/8056262909898
Smart glasses with main goal of facilitating low-threshold media and AI interaction. Has array with 5 microphones (2 in each temple, 1 in nose-bridge) and directional Bluetooth open-ear speakers with adaptive volume of up to 76dB. Uses dual (?) cameras with 12MP ultrawide. Has single-eye display via Waveguides.
Can be used for - real-time translation (of speech and text in environment) - real-time STT - speech enhancement - via head direction - makes speech of focused person brighter - Media and AI interaction - Capturing images and videos - Social media - Be-my-eyes: Voluntary helpers guide blind persons via camera output
Interaction via - Touchpad in frame - Uses gesture control - Adjust volume, standby, navigation - Dedicated recording button - Phone app - Neural Band for gesture control via EMG
Bluetooth adds latency and privacy concerns, selling point of #Xander Glasses is on-device processing. Meta seems to focus on speaker enhancement using Conversation Focus.
OrCam Hear¶
Source: https://www.red-dot.org/de/project/orcam-hear-53370
An alternative to using glasses for multi-modal input: A necklace with integrated camera and chip to perform speaker identification and speech enhancement.
Speech Transcription Glasses¶
Xander Glasses¶
Source: https://www.xanderglasses.com/xanderglasses
Glasses allow for real-time STT, displayed via binocular AR display based on Vuzix. No app connection, allowing for low-latency, real-time captioning.
Uses dual microphones with noise suppression for captioning. Claims 90% captioning accuracy. No interaction possibilities except turning it on and off. Works for people with mild to complete hearing loss.
Competes with #Meta Ray-Ban Glasses, selling point is low-latency and privacy-preserving on-device processing.
Xrai Glasses¶
Source: https://xrai.glass/
Very similar to #Xander Glasses, claim 98% transcription accuracy, but also uses Bluetooth connection for full performance.
EvenRealities G2¶
Source: https://www.evenrealities.com/de-DE/smart-glasses
Glasses with transcription, but also translation and media consumption. Uses Waveguide display like Meta Ray-Ban glasses.
Hearing Aids¶
Commercial hearing aids use a mix of classical signal processing and AI-based models. Current focus are multi-speaker scenarios, multi-directionality and environment adaption.
Signia Speech Enhancement¶
Source: https://www.signia-pro.com
No own products, but technology provider. Provide whitepaper for multi-beamformer, which should improve speech enhancement in multi-speaker scenarios. Uses phase-inversion techniques. Idea is to apply gain in speaker directions and suppression anywhere else. No "focused speaker" scenario.
Phonak AutoSense¶
Source: - https://www.phonak.com/de-de/hoerloesungen/hoersysteme/audeo-sphere - https://www.phonak.com/en-int/professionals/innovations
Speech enhancement in multi-speaker scenarios. "Direction-independent" speech enhancement, likely means ML model trained to remove background babble, running on dedicated chip
Starkey¶
Source: https://www.starkeypro.com/government/continue-learning/research-and-publications
Starkey produces AI-based speaker enhancement software, that promises improvements in multi-directional speaker sources.
Fortell¶
Source: - https://www.fortell.com/how-it-works - https://cdn.prod.website-files.com/68483ae9b9193f5347f397e0/69a1b1a1be15067025217cf0_e06ee42832504254d65e9f3f9bcf0304_Spatial%20AI%20Improves%20Speech%20Intelligibility%20for%20Hearing%20Aid%20Wearers.pdf
Recent competitor, uses high-performance TSMC chip and AI-based source separation together with noise suppression and speaker emphasize. Promises magnitude improvement in multi-speaker scenarios, even when main speaker is quieter than noise.
Over-the-Counter Earbuds¶
These products are cheaper (<1000$) and mostly prescription-free alternatives to hearing aids.
- Linner Earbugs Have 16 WDRC channels (wide dynamic range compression) that allow for separate processing and gains of different frequency bands.
- Sony CRE-E10 Uses #Signia Speech Enhancement to improve speaker quality